
Infrastructure Sprawl is Creating a Devops Nightmare
Scaling microservices without a robust orchestration strategy turns your infrastructure into a fragile house of cards. When deployments cause unexplainable downtime, rollbacks are impossible, and cloud bills vary wildly, your platform's reliability is entirely compromised.
Enterprise-Grade Kubernetes Architecture & Consulting
We design, deploy, and secure immense Kubernetes clusters that handle billions of requests. Our architects establish seamless GitOps pipelines, aggressive auto-scaling policies, and resilient multi-availability-zone topologies so your applications can survive total regional cloud outages.
Why NeoEvolution?
Zero-Downtime Deployments
Configuring rolling and canary release patterns so users never experience application interruptions.
Infinite Auto-Scaling
Engineering HPA and cluster auto-scaler logic to expand precisely during traffic spikes and contract to save cash.
GitOps Paradigm
Treating infrastructure-as-code securely with ArgoCD so your entire cluster state is defined by a single Git repo.
Recent Deliveries
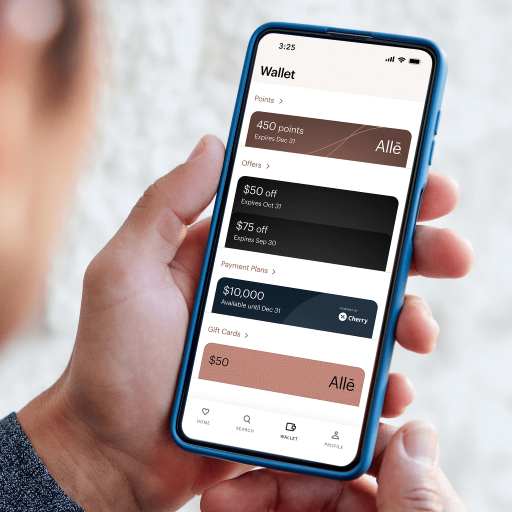
Overview
As the largest aesthetics company in the U.S., Allergan Aesthetics set out to redefine customer loyalty through a digital-first approach. The mission was ambitious: to launch a comprehensive platform that not only rewarded aesthetic treatment customers but also served as a business tool for thousands of providers and internal stakeholders.
Project Objectives
• Serve millions of patients with seamless loyalty experiences
• Enable 24/7 access to rewards, gift cards, and promotions
• Integrate real-time provider search, secure payments, and administrative tools
• Support marketing, customer support, call centers, and sales operations
Key Deliverables
NeoEvolution AI collaborated closely to deliver Allē providing staff augmentation to design and develop an intuitive ecosystem that redefined loyalty in the aesthetics space.
• $5.2B+ in annual sales and $1.6B+ net revenue
• 7.8M+ patient users, 75K+ care providers nationwide
• 3 fully-integrated systems: Consumer, Business and Admin
• Major adoption across call centers, marketing, sales, and support
• Secure, compliant infrastructure deployed at scale
• Streamlined promotions and provider visibility, increasing customer retention

React

Chakra UI

NodeJS

Typescript

Storybook

Jest

Cypress

AWS

PostgreSQL

Serverless

GraphQL

Rest

Kubernetes

Terraform

Docker

Datadog

Okta

PingID
Kubernetes & Cloud Native Consulting — FAQ
Real questions from engineering leaders evaluating our team.
Use a managed service unless you have a very specific reason not to. Self-managed control planes consume an SRE team and rarely earn back the maintenance cost. We deploy to EKS, GKE, and AKS regularly. Self-managed kubeadm/k3s/RKE only make sense for on-prem regulatory constraints or extreme cost optimization at very large scale.
Yes. Default stack: ArgoCD or Flux for app delivery, Helm or Kustomize for templating, sealed-secrets or external-secrets for secret management, and Renovate/Dependabot for image bumps. We deliver a working flow in 1–2 weeks for a single environment, then progressively roll it out across staging/prod.
Three layers, in order of impact: right-size requests/limits using Vertical Pod Autoscaler in 'recommend' mode and historical metrics; pack workloads onto spot/preemptible nodes via taints + node groups (typically 60–70% spot for stateless); use Cluster Autoscaler with scale-to-zero on dev clusters. We've consistently driven 30–50% cost reduction without performance regression.
Skeptical by default. Service mesh adds real operational cost — for most teams, the value (mTLS, retries, traffic shifting) doesn't justify the complexity. We recommend mesh only when you have specific compliance needs (zero-trust mandate), heavy multi-cluster traffic, or already-deep observability investment. Linkerd if you must, Istio if you have specialised SRE.
Carefully. Stateless apps belong in K8s; stateful systems often shouldn't. We default to managed services (RDS, Cloud SQL, MSK, Confluent Cloud) for production data plane. If your platform team specifically wants stateful K8s, we use operator-based deploys (CloudNativePG for Postgres, Strimzi for Kafka) and design backup + DR rigorously up-front.
Multi-AZ control plane (default in managed services), application-level multi-region for critical workloads, etcd backups (or rely on the managed provider's backups), and rehearsed runbooks. We do a tabletop DR exercise in the first month: simulate a region outage, walk through the runbook, find what's missing, fix it. Untested DR isn't DR.
Explore related services
AWS Architecture
Discover AWS Architecture services →Cloud & InfrastructureGoogle Cloud Architecture
Discover Google Cloud Architecture services →Cloud & InfrastructureDevOps & Docker
Discover DevOps & Docker services →Data & ArchitectureSearch & Observability
Discover Search & Observability services →
NeoEvolution AI: Where elite engineering meets exponential technology. We don't just predict the future; we build the infrastructure that runs it.
Company
Headquarters
Suite 200
2020 Winston Park Drive,
Oakville, ON L6H 6X7
Canada
Connect
hello@neoevolution.ai
© 2026 NeoEvolution AI